
2~3年的打工人状态——就这?
序在贵司的工作经历:
2021/6 - 2022/2:实习
2022/7 - 至今:
毕业后,2022 年 7 月 2 号入职贵司已经快两年了。从实习开始算的话,已经三年了。这三年来
我做了什么?
我到底学到了什么?
我变成什么样了呢?
我是如何改变的?
我的状态符合两年前、三年前我自己的预期吗?
我未来将走向何处?
借着这次转组的契机,我尝试对自己进行一次中期的总结和记录。
工作到底做了些啥
此部分是个人流水账
2021/6 ~ 2022/2实习期主要是参与 TiDB Data Migration(DM)的开发的维护,主要和 MySQL 的 binlog 打交道。
其中一个大的工作就是重构一部分 syncer 模块。在修这个 pr 的时候,瞅着增量同步那一块主流程代码怎么看怎么不爽,各个函数含义不清,完全不知道要怎么改。。。所以直接来了一波重构(track issue),当时的 mentor(Lei 哥)竟然直接同意我这个菜鸡做了😂。一干就是几个月。。。从此对重构远古代码的人产生了敬畏之心。
另一个大的工作是优化 DM 的 precheck 功能(track issue) ...

DM 数据旅程 02:分库分表悲观协调——03reSync
一、概述在分库分表同步的过程中,不同的 DDL 之间,还会穿插着各种各样的 DML 语句,这些 DML 语句要如何处理呢?今天就来看看它们的处理过程——reSync。
本节先介绍 reSync 的总流程,然后分为四个部分介绍 reSync:
一阶段:reSync 之前
开启 reSync
二阶段:reSync 之后
关闭 reSync
本节内容皆参考 DM v6.0,对现在而言,有可能已过时,欢迎大家提出意见~
二、Overview
进入 lock 阶段后,在第一次 sync 的时候,会跳过被 active 影响到的 targetTable 对应的 DML
在 Lock resolved 之后,会回到第一次进入 lock 的 binlog Location 点,进行 reSync,把之前 skip 的 DML 重新 sync,这个阶段会跳过上次执行过的 DML。
原理两种 DML 互相隔离,不会互相影响。
三、过程1、一阶段Skip在 handleRowsEvent 的时候,判断该 event 是否需要 skip:
通过 targetTable 得到对应的 group
...

DM 数据旅程 02:分库分表悲观协调——02Lock -> Resolve Lock
一、概述介绍了与悲观协调有关的各个数据结构之后,接下来将介绍一个 DM 系统从接受到第一条分表 DDL 开始,到所有该 DDL 对应的 Lock resolved 的全过程。
本节内容皆参考 DM v6.0,对现在而言,有可能已过时,欢迎大家提出意见~
二、Overview假设现在起了 master 和两个 Worker,两个 Worker 分别绑定两个 Source(s1,s2),每个 Source 有两个分表(t1,t2),这四个表会 route 到一个 target table(tarTbl)中。在 DDL 到来之前,两个 worker 会创建好 ShardingGroupKeeper,里面只有一个 target table,两个 source table。
两个 Worker 先后收到两个 Source 四个分表的同一条 DDL,表示为:
DDL1:表示对 s1.t1 的 DDL。
DDL2:表示对 s2.t1 的 DDL。
DDL3:表示对 s1.t2 的 DDL。
DDL4:表示对 s2.t2 的 DDL。
三、具体过程
本小节 worker 对 DDL 的处理 ...
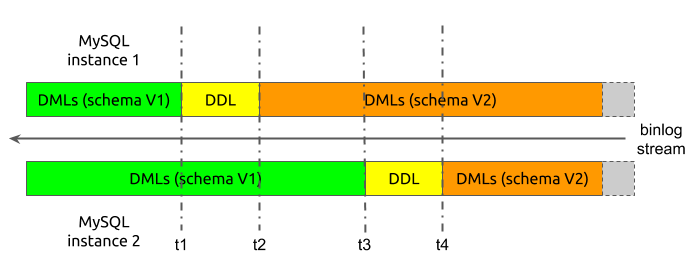
DM 数据旅程 02:分库分表悲观协调——01准备过程
一、概述分库分表的悲观协调方法是 2018 年开发的特性,是 DM 首次支持 MySQL 分库分表的迁移。由于分库分表在各个公司中的应用实在太过广泛,所以只有在支持分库分表迁移后,DM 才有了工程实践的意义,否则只能算作一个玩具。这对 DM 来说意义重大。
由于悲观协调的内容庞大,本节只讲述悲观协调的准备过程:
Master 的准备过程
Worker 的准备过程
以及在悲观协调过程中至关重要的结构体:
Lock
Info
Operation
ShardingMeta
ShardingGroup
…
注:为了专注于我们的目的(悲观协调),本文不会对无关代码进行解读
这一节外链中的代码,读者可能会产生这个逻辑为什么是这里的疑问。这是因为本节并没有完全按照顺序读代码。所以读者可以仅带着学习的心态阅读本节,暂时不需要知道它为什么在代码的这个地方。在下一节中会顺序阅读代码
本节基于 DM release-6.0.0
二、Master1、Pessimist 和 LockKeeper
NewPessimist:Pessimist 是 Master 处理悲观协调的结构体,其中最重要 ...

DM 数据旅程 01:第一次 start task
一、概述本文以 start task 为目的,带着读者从 0 到 1 启动一个数据迁移任务,旨在让读者了解到最基础的 DM 逻辑。本文将直接参照集成测试 start_task 的过程,从以下几个方面展开:
Start dm-master
Start dm-worker
绑定 source 和 dm-worker
Start task
注:为了专注于我们的目的(start task),本文不会对无关代码进行解读
大家可使用 start/stop 流程 辅助阅读
由于写这篇的文章的时间是 2021 年 12 月份,所以所有的链接都是原 DM repo 的😂
二、start dm-master
./dm-master(in run_dm_master) 启动二进制文件,即调用 main 函数,其中 master-server start
go electionNotify:这个是为了等待 etcd election 成功,并在其成功后做⬇️
DM master 中内嵌了一个 etcd,用于存储各种元数据,并且借此保证 DM master 的高可用。后面非常多的数据存储都会用 ...

DM 数据旅程 00:序言
背景在此之前已经有官方很多关于 DM 的优秀文章了,比如
TiDB Ecosystem Tools 原理解读系列(三)TiDB Data Migration 架构设计与实现原理
DM 源码解读
这些文章从原理方面非常详尽地介绍了 DM 的相关功能,是非常好的学习资料。但是
它讲述的内容跨度较大,对读者有一定的门槛,DM 源码阅读系列文章(一)序:背景知识
编辑时间太过久远,已经过去两年多了。DM 新增了一些新特性,对很多旧功能也进行了更新优化。所以原文中有很多内容已经过时(但大部分仍有参考价值)。例如:DM 使用 Dumpling 替换了 MyDumper,新增乐观模式等等。
而外部的文章则大部分集中在 DM 的使用上而不是实现上。
基于此,我想开一个坑《DM 数据旅程系列》,每一篇文章将以一个个小功能为线索,带大家理解 DM 中的各种实现。如果要讲的功能太大,也会拆分成小模块放出。每一步都会尽量放出 GitHub 地址,方便大家跟踪学习~
数据旅程出自于龙少 PPT 中提到的用户旅程和数据旅程,指我们可以通过数据(字节)传输的途径。在看一段代码时,我们可以思考这个字节是从哪 ...

2022年终总结——幸运开心的一年
第一次写年终总结呀,尝试记录一下。一年下来还真发生了不少事。看看自己有啥收获有啥成长。
工作先说说工作吧。从南大毕业后,我去了 PingCAP(贵司)工作,现在在贵司的 DM(Data Migration)团队工作,差不多就在数据导入、数据迁移以及其对应的云上版本这些地方搬砖。去年就有在贵司实习,主要在维护 DM,也就是怎么把一条 binlog 写到下游 TiDB 里面,和 MySQL binlog 打交道比较多。今年入职后,顺应公司的战略,主要在 tidbcloud.com 上 CRUD,帮助用户在 cloud 上导入或迁移数据,和 k8s、CRUD 以及用户体验打交道比较多。
简单总结一下学到的东西吧,从实习到现在:
单元测试、集成测试
多线程代码
review 代码
写设计文档
理解一个需求是任何工作的第一步
对一个需求进行项目管理,以尽可能地按时交付(当然现在还做的不够好。。。)
学习了 K8s/CRD/Operator/AWS/Pulumi 相关的知识,能看懂代码,并编写简单的代码
更多地考虑用户体验
。。
再谈谈工作的感受。对于我这第一份正式的工作,我是非常满意我当前的 ...